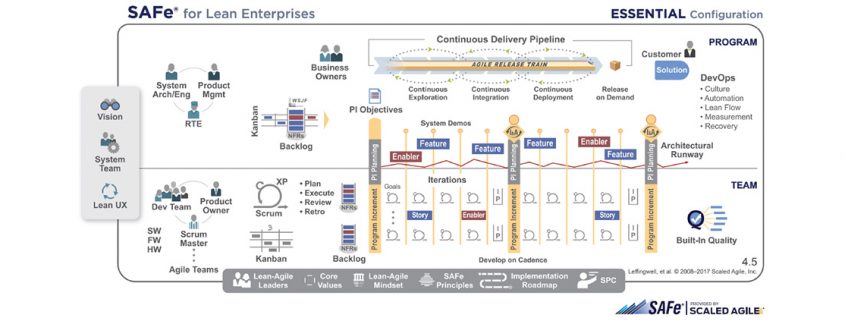
Als je enige gereedschap een hamer is…
De omgeving van organisaties verandert met een toenemende snelheid. Complexiteit en onzekerheid vieren hoogtij. Maar de toolset die management gebruikt voor het managen en vormgeven van hun organisaties verandert maar heel langzaam. Er is een toenemend gat tussen de toepasbaarheid van de gebruikte tools en de probleem domeinen van moderne organisaties. Hoe kunnen we vaststellen in welk domein we zitten en of we passende tools gebruiken?
Er is geen ontkennen aan dat organisaties opereren in een wereld van onzekerheid en continue verandering. Windows of opportunity openen en sluiten steeds sneller. Een concurrentievoordeel voor langere tijd vasthouden is tegenwoordig behoorlijk lastig. Het lijkt ook duidelijk dat de meeste organisaties slecht toegerust zijn om te gaan met snelle veranderingen. Een indicatie daartoe is de gemiddelde levensverwachting van organisaties. Die lijkt in een alarmerend tempo af te nemen. Professor Richard Foster of Yale University leidde een Innosight onderzoek dat aantoont dat een 61 jarige levensverwachting voor het gemiddelde bedrijf in de S&P 500 index in 1958 afnam tot 25 jaar in 1980, tot slechts 18 jaar nu. Sterker nog, in dit tempo zal in 2027 meer dan 75% van de S&P 500 uit bedrijven bestaan waar je nu nog nooit van hebt gehoord. Dat klinkt best alarmerend toch?

Er is duidelijk werk aan de winkel voor organisaties. Zelfgenoegzaamheid is je grootste vijand in deze wereld, en is een één-richting straat naar irrelevantie. Het bedrijvenkerkhof ligt vol met bedrijven die of te laat of helemaal niet op verandering gereageerd hebben. We pretenderen niet het wondermiddel in handen te hebben dat elke organisatie omtovert tot een veerkrachtige adaptieve organisatie die alles aankan. Maar de eerste stap is om te beoordelen in welk probleemdomein we zitten en of de tools die we nu gebruiken daar eigenlijk wel geschikt voor zijn. Helaas blijven veel organisaties hardnekkig vasthouden aan de tools die ze kennen zoals hiërarchie, centralisatie, focus op efficiency, regels en procedures, lineaire planning, etc. Er is op zich niks mis met deze tools, maar ze zijn ontworpen voor organisaties die 100 jaar geleden bestonden. Veel managent tools zijn min of meer nog steeds de erfenis van Frederick Taylor’s Scientific Management en Henri Fayol’s functies en principes van management. De wereld is echter behoorlijk veranderd sindsdien. In Westerse economieën zijn er niet veel branches meer waar deze tools nog goed werken.
Elke organisatie, afdeling, team, of proces bevind zich in een specifiek probleemdomein, elk met zijn eigen passende aanpak en tools. Dus hoe kunnen we vaststellen in welk domein we ons bevinden? Een nuttige tool hierbij is het Cynefin framework. Cynefin onderscheid vier hoofddomeinen, en een vijfde die disorder heet, die elk context beschrijven in termen van de relatie tussen oorzaak en gevolg. De vier hoofddomeinen heetten obvious (I geef nog steeds de voorkeur aan de oude term ‘simple’), complicated, complex, and chaotic. Het disorder domein is bedoeld voor als je niet kunt vaststellen in welk domein je bent.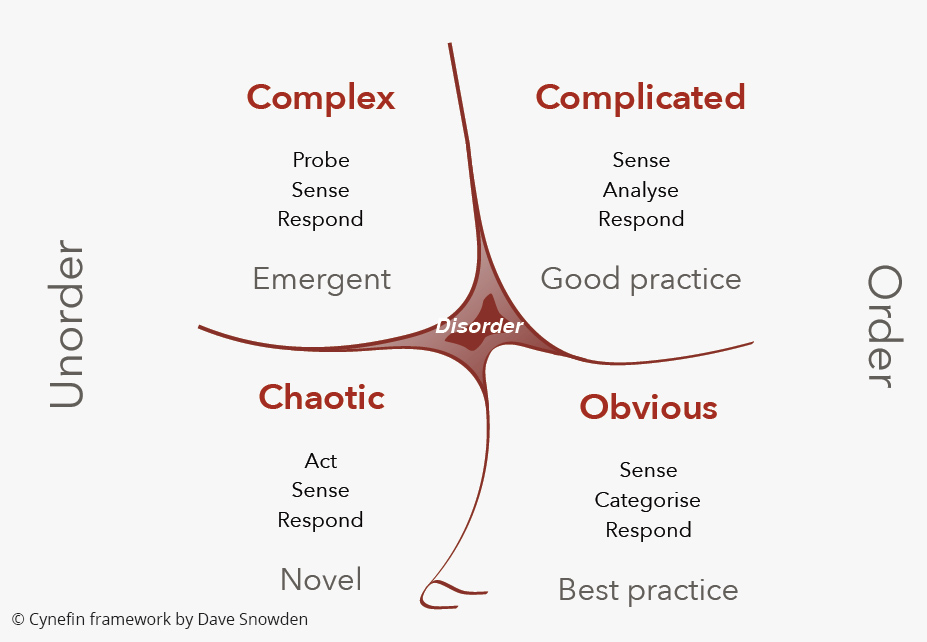
Voor een gedetailleerde beschrijving van het Cynefin framework verwijs ik naar het uitstekende Harvard Business Review artikel van de bedenker van het framework, Dave Snowden. Voor dit artikel houden we de uitleg kort: In het Obvious domein kunnen we het probleem eenvoudig categoriseren en dan de juiste checklist of procesbeschrijving erbij pakken. Omdat de omgeving in dit domein redelijk stabiel en voorspelbaar is, kunnen we ons richten op het optimaliseren van best practice processen. Een eenvoudig lening aanvraagproces is een goed voorbeeld hiervan.
In het Complicated domein is het allemaal niet zo simpel en voorspelbaar. We hebben experts nodig die de situatie analyseren voor we kunnen reageren. Dit is het domein van de experts en kenniswerkers. Meestal is er nog steeds een significant verband tussen oorzaak en gevolg, maar oorzaak en gevolg kunnen in plaats en tijd van elkaar gescheiden zijn, wat het lastig maakt het verband te zien. Dit wordt versterkt door typische management structuren zoals silo’s en KPI’s. We nemen een beslissing in één silo, laten we zeggen de afdeling Verkoop, dat een ongewenst effect als gevolg heeft op een andere silo, laten we zeggen Operations. We zien de relatie tussen oorzaak en gevolg echter niet omdat het in een andere afdeling gebeurt (plaats), en misschien met een vertraging (tijd). Onze focus op verkoop, versterkt door een KPI die slechts verkoop als output meet, zorgt er nog meer voor dat we het negatieve effect op een andere afdeling missen, omdat je die alleen kunt meten met een andere KPI dan degene waarop wij worden afgerekend.
De Obvious en Complicated domeinen worden de geordende domeinen genoemd. Veel organisaties denken zich in de geordende domeinen te bevinden, terwijl een toenemend aantal situaties in organisaties, teams, en processen eigenlijk in het complexe domein valt, wat een geheel andere aanpak vereist. Want in het Complexe domein werken ‘good’ of ‘best practices’ niet. De omgeving is niet stabiel noch voorspelbaar, en daardoor kunnen we niet simpelweg aannemen dat wat in het verleden werkte ook nu, in een andere context, zal werken. En we kunnen de toekomst ook niet plannen in het complexe domein. We kunnen het alleen ontdekken door te experimenteren. De relatie tussen oorzaak en gevolg kan er wel zijn, maar is meestal pas achteraf te constateren. Dit gaat tegen de intuïtie van veel managers in die dit dan ook maar moeilijk kunnen accepteren. Er is een dominante tendens om de toekomst te kunnen willen controleren en voorspellen, zelfs in situaties waar dat niet mogelijk is, en zelfs als we keer op keer constateren dat onze zorgvuldig opgestelde plannen al heel snel niet uit blijken te komen.
Laten we het factureringsproces als voorbeeld nemen. De meeste organisaties verkopen iets, dus facturering is een gebruikelijk proces. Je zou kunnen denken dat facturering een stabiel voorspelbaar statisch proces dat makkelijk kan worden afgehandeld en geoptimaliseerd door een geautomatiseerd proces. En dat klopt. Maar het gevaar is dat management nu alleen nog maar op regels e processen als middel gaan vertrouwen. Het gaat niet om de 95% aan facturen die correct verwerkt worden, de grootste impact ligt in de 5% waar iets mis gaat of die uitzonderlijk zijn. Dit zijn de gevallen die de meeste tijd kosten, en die een gevaar zijn voor de reputatie van het bedrijf als ze niet adequaat afgehandeld worden. Je kunt de uitzonderingen niet op dezelfde manier behandelen als de voorspelbare gevallen. Maar dat is wel wat de meeste organisaties doen. Als er een uitzondering gevonden wordt, dan creëren we een nieuwe regel. Als de klant klaagt over een foute factuur, dan passen we het proces aan. Tot de volgende uitzondering. En de volgende. Op deze manier worden de systemen langzaam steeds moeilijker te doorgronden en te onderhouden, steeds lastiger aan te passen aan nieuwe situaties, en erg kostbaar. En dan nog worden we telkens weer verrast door nieuwe uitzonderingen die nog niet afgedekt worden door regels. Wat de situatie nog erger maakt is dat de afhandeling van klachten van klanten over foute facturen hetzelfde probleem kent: Klantenservice medewerkers volgen over het algemeen een strikt script dat standaard situatie prima afdekt. Maar de frustratie van klanten komt niet van de standaard gevallen, maar van de uitzonderingen en het onvermogen van klantenservice medewerkers het probleem snel op te lossen
Klinkt dit bekend? Het is een continue bron van zendtijd voor consumentenprogramma’s op tv: telecombedrijven, energiemaatschappijen, en verzekeringsmaatschappijen die doorgezaagd worden over hun onvermogen om niet-standaard situaties, die echter voor klanten en de kijker zo duidelijk lijken, op een adequate manier af te handelen. Het is een klassiek voorbeeld van de verkeerde tool voor het probleemdomein. En toch lijken deze bedrijven er nooit van te leren. Wat is het standaard antwoord van de woordvoerder of manager die dapper genoeg is om voor de camera te verschijnen als hun gevraagd wordt hoe ze dit soort problemen in de toekomst gaan vooromen? “We gaan het proces analyseren en verbeteren”. Zucht…
En dat brengt ons bij het belangrijkste leerpunt van dit artikel: als je niet weet in welk domein je situatie zich bevind, dan zul je het waarschijnlijk behandelen als het domein van je voorkeur of ervaring. En in veel gevallen blijkt dat de verkeerde. Je zult dan tools gebruiken die op zich niet fout zijn, maar niet geschikt voor het betreffende probleem. Ten slotte, als je enige gereedschap een hamer is, dan lijkt elk probleem op een spijker…